
De opmars van kunstmatige intelligentie zorgt ook voor een aanslag op het gebruik van water en energie. Eén plaatje met AI maken? Dat kost evenveel stroom als het opladen van je mobieltje.
Het is een van de donkere kanten van kunstmatige intelligentie (AI): het trainen van de taalmodellen en het in de lucht houden van de bij het grote publiek populaire chatbots kosten grote hoeveelheden energie en water. Lang is dit een onderbelicht aspect geweest bij AI. Sterker, meestal ging het juist om de positieve effecten die AI kan hebben op het mondiale energieverbruik. Energiebedrijven, maar ook beheerders van datacentra wijzen op de nuttige bijdrage van AI bij het optimaliseren van vraag en aanbod. Een ander voorbeeld is het gebruik van AI bij het selecteren van ideale plekken voor zonne- of windenergie-installaties.
Inmiddels heeft de politiek ook aandacht voor de andere kant van de medaille. Zo gaat de Europese AI-wet eisen stellen aan de makers van AI-systemen. Zij zullen gedetailleerde informatie moeten gaan leveren over de energieconsumptie, zowel tijdens de training van de systemen als tijdens het gebruik door klanten. Ook sommige Nederlandse politieke partijen (GroenLinks-PvdA, Volt, D66) hebben aandacht voor het energieprobleem van AI. Zo wijst D66 in zijn laatste partijprogramma op AI’s afhankelijkheid van grote hoeveelheden elektriciteit, stroom en eindige grondstoffen. ‘Dit dreigt de klimaatcrisis juist te versterken’, aldus de partij.
Maar over wat voor hoeveelheden gaat het? Zal het totale energieverbruik van AI-toepassingen in 2027 echt even groot zijn als dat wat heel Nederland jaarlijks consumeert, zoals Alex de Vries, onderzoeker aan de Vrije Universiteit Amsterdam, onlangs nog voorspelde? En hoe zit het met het waterverbruik? Een antwoord is nog niet zo eenvoudig te krijgen, wat te maken heeft met het gesloten karakter van AI-modellen en het gebrek aan transparantie bij de uitbaters ervan. Veel komt dus aan op schattingen, aannames en benaderingen. De Volkskrant dook in de cijfers.
Waterverbruik: schiet omhoog
Vraag ChatGPT zelf hoeveel water het per prompt (een vraag of een opdracht) verbruikt, en het schrijft terug: niets natuurlijk! Ik ben tenslotte digitaal, dus ik heb geen water nodig. Het antwoord van iemand die geen water drinkt, maar wel elke dag doucht.
Want taalmodellen zoals ChatGPT gebruiken wel degelijk water. Dat zit hem in de computers (servers) in datacentra waarop de software draait. Elke vraag aan ChatGPT kost rekenkracht van servers. Om oververhitting te voorkomen moeten die worden gekoeld, op warme dagen meer dan op koude. Overigens geeft het programma dat zelf ook wel toe, later, maar het schrijft dat het afhangt van het soort datacentrum en waar het staat om precies te berekenen hoeveel water een opdracht kost.
Taalmodellen gebruiken op twee manieren water voor het koelen van servers. Eerst worden ze getraind op enorme hoeveelheden tekst. Dat kost enorme hoeveelheden rekenkracht. Minder computerinspanning kost het om een vraag te beantwoorden van een gebruiker, dan is het model immers al getraind.
Dat het waterverbruik van grote techbedrijven enorm stijgt sinds de toenemende populariteit en gebruik van taalmodellen, blijkt uit de getallen die de bedrijven zelf publiceren. Zo steeg het waterverbruik van Microsoft in 2022 met 34 procent vergeleken met 2021, tot ruim 6,4 miljard liter. Bij Google nam het verbruik in dezelfde periode met 20 procent toe. Veel van de servers waarop de programma’s van OpenAI (waarvan ChatGPT is) draaien, zijn van Microsoft.

Shaolei Ren, onderzoeker aan de Universiteit van Californië, schat in een studie dat er een halve liter koelwater nodig is voor elke vijf tot vijftig vragen aan ChatGPT, afhankelijk van waar de servers staan en het seizoen. Die schatting is inclusief indirect watergebruik, bijvoorbeeld om de energiecentrales te koelen die zorgen voor de stroomvoorziening van datacentra.

En dan is er nog het trainen van het model. Volgens de Universiteit van Californië kostte dat in het geval van GPT-3 (een van versies van het taalmodel achter ChatGPT) minimaal 700 duizend liter water, al zijn er ook schattingen van vijf keer zoveel: 3,5 miljoen liter. Dat laatste scenario zou genoeg zijn om 75 Nederlanders een jaar van drink-, douche- en wc-water te voorzien of om een kleine vierduizend tuinen een jaar lang te sproeien. OpenAI bracht intussen ChatGPT 3,5 en ChatGPT-4 uit. Al die modellen moeten worden getraind. Hoogstwaarschijnlijk met nóg meer water, omdat de modellen weer een stuk groter zijn dan hun voorganger.

In juli 2022, de maand dat OpenAI bekendmaakte dat GPT-4 getraind was, pompte het bedrijf 43,5 miljoen liter water in de datacentra in Des Moines in de Amerikaanse staat Iowa, volgens de Des Moines Water Works. De stad overweegt sinds vorig jaar toekomstige dataprojecten alleen nog goed te keuren als Microsoft piekbelasting van het waternetwerk kan voorkomen of terugbrengen, schreef de Des Moines Water Works.

Energieverbruik: één AI-plaatje is één keer mobiel opladen
Niemand die beter weet wat het energieverbruik van hun modellen is dan de partijen die de rekening moeten betalen. Het probleem, legt Luís Cruz (onderzoeker aan de TU Delft) uit: partijen als Google of OpenAI vertellen niet hoeveel computerkracht, en dus energie, er nodig is om hun zogenoemde LLM’s te trainen. LLM’s (Large Language Models) liggen aan de basis van producten als Bard of ChatGPT en zijn de laatste jaren aanzienlijk in omvang gegroeid. Hoe groter het model, hoe beter de prestaties, is de aanname.
Die grootte wordt aangeduid in de hoeveelheid parameters, de interne connecties binnen het model waarmee het patronen leert op basis van de trainingsdata. Of eenvoudiger gezegd, de hoeveelheid ‘knoppen’ waaraan het programma kan draaien om een goede tekst of afbeelding te genereren. De hoeveelheid parameters van LLM’s zijn in vijf jaar tijd gegroeid van pakweg honderd miljoen naar 500 miljard (in het geval van Googles taalmodel PaLM).
Harde cijfers van de marktleiders over CO2-uitstoot ontbreken, maar onafhankelijke onderzoekers zijn de laatste jaren wel aan het rekenen geslagen in diverse studies. Een van de eerste is al wat jaren oud. Onderzoekers van de Universiteit van Massachusetts schatten in 2019 dat de training van een LLM neerkomt op de uitstoot van 280 ton CO2. Oftewel: evenveel als 15 Nederlandse huishoudens in een jaar tijd uitstoten.

Sindsdien zijn de modellen alleen maar groter geworden. De laatste studies komen dan ook uit op veel meer uitstoot: 500 ton CO2 voor GPT-3. Ook TU-onderzoeker Cruz gaat uit van minimaal dit getal: GPT4 is alweer groter dan GPT-3.
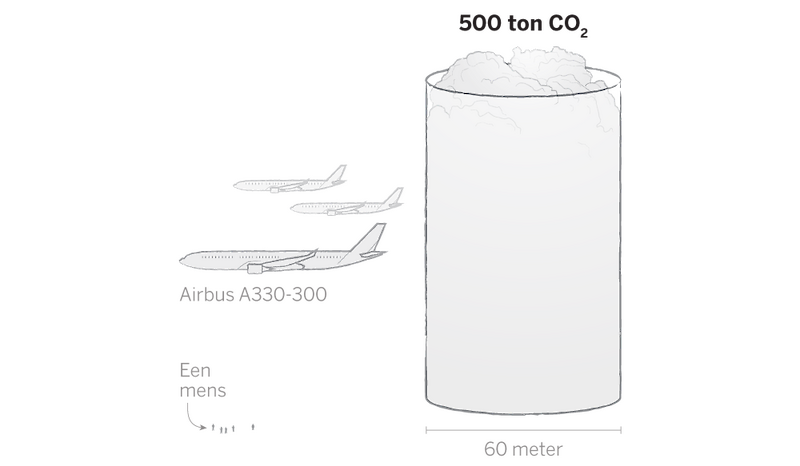
En, net als bij het waterverbruik, blijft het hier niet bij. Als het systeem eenmaal is getraind, gaan klanten er daadwerkelijk mee aan de slag. Dan zal de energie die de AI-tool nodig heeft om zijn werk te doen over het algemeen ongeveer gelijk zijn aan die van de training, is een heel grove schatting van Cruz. Op het moment dat een tool, zoals in het geval van ChatGPT, viraal gaat, is het totale verbruik natuurlijk aanzienlijk hoger.
Wat als een paal boven water staat, is dat interactie met een chatbot veel meer energie kost dan een ouderwetse zoekopdracht via Google. Sam Altman van OpenAI benoemde op Twitter al de torenhoge kosten die gepaard gaan met het converseren van ChatGPT. Ook Googles moederbedrijf Alphabet noemt die hoge kosten. In een interview met persbureau Reuters heeft een topman het over een ‘factor tien’ als gevolg van de benodigde extra computerkracht.
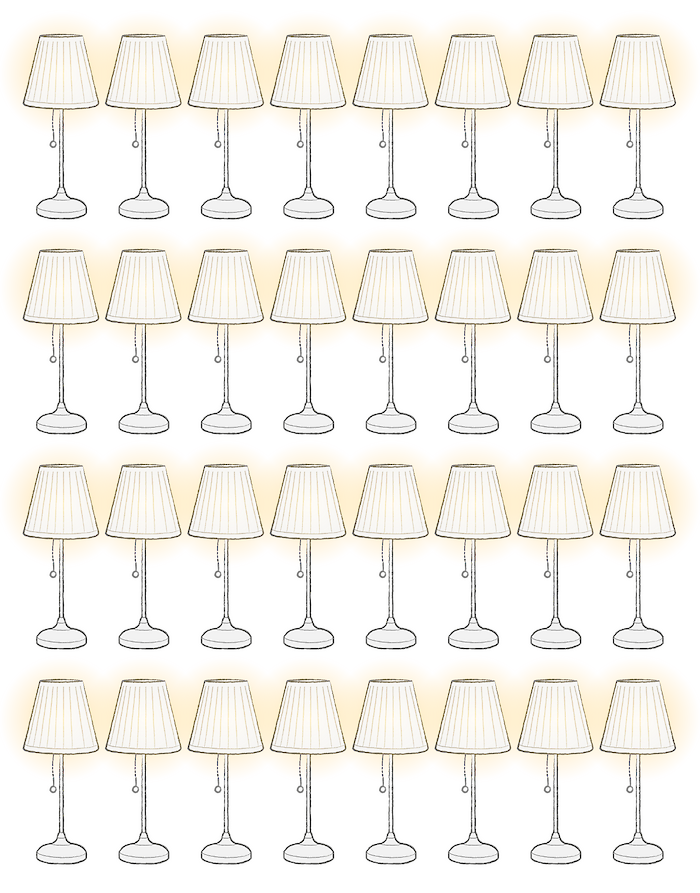
Recent onderzoek van de AI-start-up Hugging Face en de Carnegie Mellon Universiteit geeft voor het eerst gedetailleerd inzicht in het energieverbruik op het moment dat iemand daadwerkelijk een chatbot of ander AI-programma gebruikt. Per duizend vragen zou een programma als ChatGPT zo’n 0,042 kWh energie verbruiken. Dat is ongeveer evenveel als een ledlamp die zeven uur lang aanstaat.

Overigens is het genereren van tekst veel minder energie-intensief dan het maken van AI-plaatjes, blijkt uit dezelfde studie. Die laatste taak kost 1,35 kWh per duizend afbeeldingen, oftewel 32 keer zoveel als het genereren van tekst. Eén AI-plaatje staat daarmee gelijk aan één keer een mobieltje opladen.
Vermoedelijk zal niemand daarbij stilstaan als hij vol enthousiasme programma’s als Midjourney of DALL-E aan het werk zet om in een paar seconde iedere gewenste afbeelding te laten maken.
‘We hebben allereerst nu een industrie nodig die duidelijk is over haar uitstoot’, zegt Cruz. ‘AI-technologie is in handen van een paar grote bedrijven, die winsten kunnen maken met onze data. Het minste dat je daarvoor kunt terugverwachten is transparantie.’
Daarnaast ziet de onderzoeker ook technische oplossingen om modellen efficiënter te laten werken: ‘AI-bedrijven kiezen nu voor de gemakkelijkste oplossing. Het is alsof je iedere dag met een grote bus naar de bakker gaat om één broodje te halen.’ Zo heb je echt niet altijd alle data nodig om een model te trainen en zou zuiniger hardware ook kunnen helpen, denkt Cruz.
Een lichtpuntje is dat ook de AI-industrie zelf lijkt terug te komen van het idee om steeds maar grotere modellen te ontwikkelen. Zo zei Altman vorig jaar nog: ‘Ik denk dat we aan het einde van het tijdperk zitten van gigantische modellen. We zullen ze op andere manieren beter maken.’